


In June 2022, we accomplished a major breakthrough by integrating container level support for AKS and EKS into the Cado platform using a non-persistent agent. This development is a game changer for serverless incident response as it eliminates the need for persistent agents to capture forensic details from Kubernetes and Docker containers. Our primary goal was to create a unified architecture that could enable our team to add new Managed Kubernetes acquisition support with minimal coding effort, and this integration proved successful. We were able to reduce the time required to build a feature from two weeks to just one day, which is a significant achievement for our team.
Unfortunately, we encountered a significant setback during our internal testing when we realized that the system was incredibly slow. Retrieving containers within a pod was taking an excessive 120 seconds, which is unacceptable when dealing with security incidents. As time is of the essence in such situations, waiting for two minutes to identify the compromised container goes against our core strength of reducing the Mean Time to Response during security incidents.
Below we’ve set out how we managed to solve this problem to make retrieving data of a compromised container lightning fast.
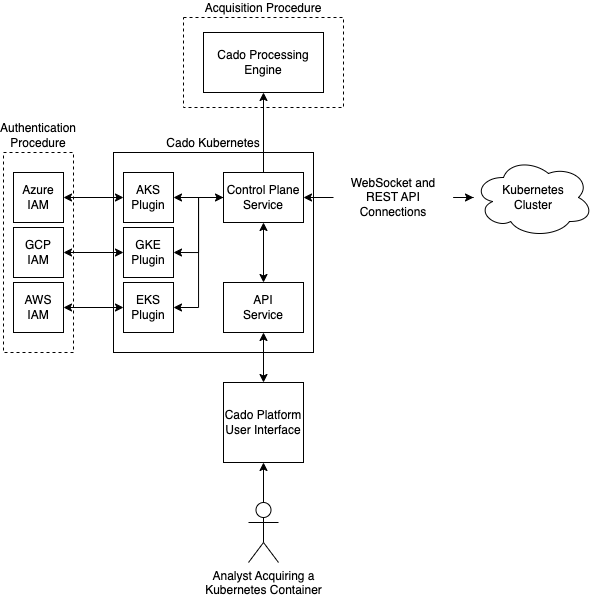
The architecture of Cado’s Kubernetes stack, while complex, allows us to add support for Managed Kubernetes Services at lightning speed.
Authentication
Each managed service has its own method for authenticating with the cluster's control plane API. While some services, like AKS, make it relatively simple to obtain a token, others, like EKS and GKE, require multiple command line calls to generate the necessary authentication credentials. As a result, handling I/O and resources for child processes can become a bottleneck in the authentication process. To address this, rewriting the authentication code using managed Python code was the most obvious solution to optimise and improve efficiency.
Rewriting the GKE Authentication Process
Rewriting authentication for GKE was actually quite simple. Even though there are no public sources available for the GCP CLI, it's packaged as a Python site-package with sources that we can use. After analysing the command line code, we discovered that we only needed the Service Account email address to call the Google Cloud IAM SDK and obtain a token that could be passed to the Kubernetes SDK.
This command:
<code>gcloud container clusters get-credentials {cluster} --zone {zone}</code>
becomes this Python code:
from google.cloud.iam_credentials import IAMCredentialsClient
auth_token = IAMCredentialsClient(gcp_credentials).generate_access_token(
name='projects/-/serviceAccounts/myserviceaccount@email.com',
delegates=['projects/-/serviceAccounts/myserviceaccount@email.com'],
timeout=3600.0,
scope=['https://www.googleapis.com/auth/cloud-platform']
)
Rewriting the EKS Authentication Process
Rewriting the authentication process for EKS presented more of a challenge, as AWS has obscured the way in which they generate a token. They intercept their own API calls to add custom headers and data to the API request, including the cluster name. However, we were able to utilise this cluster name to call the `presigned_url` generate API, which allowed us to append the necessary `k8s-aws-v1` header and obtain the token we needed. While it was a more difficult task compared to GKE, we were ultimately successful in improving the authentication process.
This command:
<code>aws eks update-kubeconfig --name {cluster} --region {region}</code>
becomes this Python code:
import base64
import boto3def get(params, context, **kwargs):
if "x-k8s-aws-id" in params:
context["x-k8s-aws-id"] = params.pop("x-k8s-aws-id")def inject(req, **kwargs):
if "x-k8s-aws-id" in request.context:
req.headers["x-k8s-aws-id"] = req.context["x-k8s-aws-id"]sts = boto3.client(
'sts',
region_name='{region}',
endpoint_url='https://sts.{region}.amazonaws.com'
)sts.meta.events.register("provide-client-params.sts.GetCallerIdentity", get)
sts.meta.events.register("before-sign.sts.GetCallerIdentity", inject)data = sts.generate_presigned_url(
"get_caller_identity",
Params={"x-k8s-aws-id": 'my-cluster'},
ExpiresIn=60,
HttpMethod="GET"
)
encoded = base64.urlsafe_b64encode(data.encode("utf-8"))
auth_token = f'k8s-aws-v1.{encoded.decode("utf-8").rstrip("=")}'
Exec and WebSockets
After optimising the authentication code for EKS and GKE, I was disappointed to find that the Kubernetes SDK was spending more time in subprocess calls than network requests. This was surprising since I thought authentication was the bottleneck. However, this performance profile was created after the authentication rewrite, so I needed to investigate further. I realised that the `exec` command was the only exception that wasn't using a simple REST API request. It was time to delve into how Kubernetes SDK was communicating with the control plane API to figure out how to make requests faster than 5 seconds.
Reverse Engineering the Kubernetes Exec Protocol
Although most requests use a REST API that is well-documented, the `exec` command is an exception. It uses a largely obsolete protocol called SPDY, which has been abandoned by Google. However, the Kubernetes Python SDK uses WebSockets for connections, which is a still-current standard. While the `exec` API endpoint is not widely documented, I reverse-engineered the protocol through trial and error.
When communicating with the control plane API through the `exec` command using WebSockets, the packet sent by the control plane comprises three parts: [opcode][channel][data]. The opcode is an ABNF value that specifies the message type, such as CLOSE, BINARY, or TEXT. The WebSocket library in Python uses the ABNF class to abstract this aspect of the protocol. The channel determines which output stream is being sent by the control plane, with stdout or 1, stderr or 2, and control plane output, which I call stdcpl or 3.
We can represent the Channel as a simple Python enum, and then use the WebSocket library in Python to send the request, which typically looks like this:
<code>wss://{cluster_endpoint}/api/v1/namespaces/{namespace}/pods/{pod}/exec?stdout=1&stderr=1&tty=0&container={container}&command={command}</code>
And that’s pretty much it, the WebSocket connection will respond with the packets, which we can filter depending on the Channel bytecode.
Putting this all together forms the latest version of the Cado platform’s Kubernetes stack, which in addition to these speed increases, includes:
- Google Kubernetes Engine support
- A refreshed User Interface
- More secure credential management
What this Means for the Customer
Now that we have successfully solved the slow response time issue, what does this mean for our customers? The answer is simple: faster and more efficient incident response in Kubernetes workloads. With the average response time per request being 111 seconds before making these changes, and the rewrite average being just 3 seconds, the difference in response time is a staggering 108 seconds per request. This translates to a percentage speed increase of 97%, which is an enormous improvement.
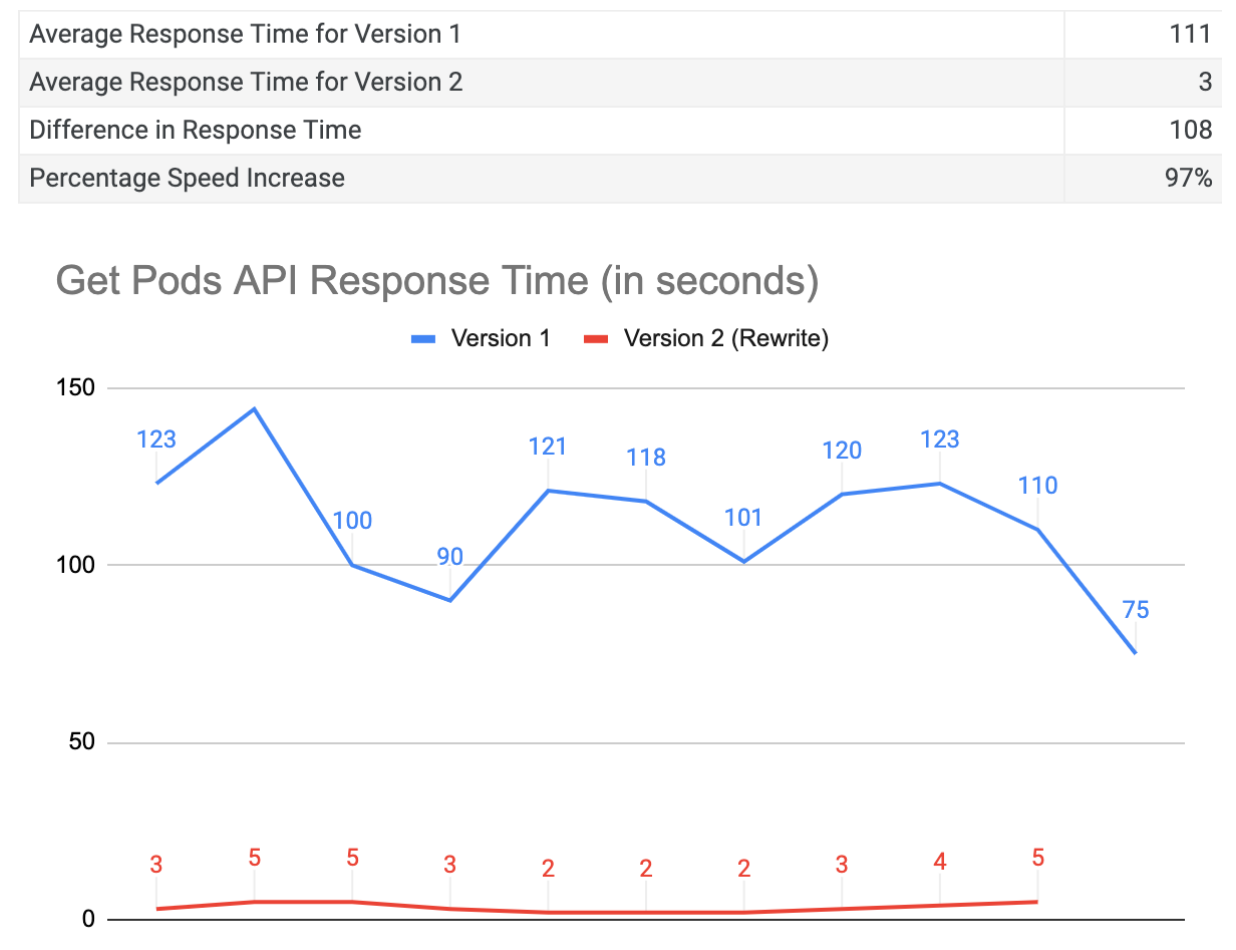
In practical terms, this means that our customers can expect a much quicker response time in the event of a security incident. Instead of waiting for minutes to choose the compromised container, the process is now lightning fast, taking just a few seconds. This is especially critical in today's fast-paced, constantly evolving threat landscape, where every second counts.
By reducing the mean time to respond, we are not only providing our customers with peace of mind, but also helping them to mitigate the potential damage that can be caused by a security incident. Faster response times mean that security incidents can be contained and resolved more quickly, minimising the impact on business operations and reducing the risk of sensitive data being compromised.
If you fancy working on complicated problems like this, see our job listings - we’re hiring!
If you want to try out our platform for responding to security incidents across Containers and VMs in AWS, Azure and GCP - you can grab a free trial here.